1,500개 이상의 학습 시간 측정 데이터를 포함한 시뮬레이터 오픈소스 공개 (https://github.com/VIA-Research/vTrain)

(대전=세종충청뉴스) 송윤영 기자 = 최근 챗GPT, 딥시크(DeepSeek) 등 초거대 인공지능(AI) 모델이 다양한 분야에서 활용되며 주목받고 있다. 이러한 대형 언어 모델은 수만 개의 데이터센터용 GPU를 갖춘 대규모 분산 시스템에서 학습되는데, GPT-4의 경우 모델을 학습하는 데 소모되는 비용은 약 1,400억 원에 육박하는 것으로 추산된다. 한국 연구진이 GPU 사용률을 높이고 학습 비용을 절감할 수 있는 최적의 병렬화 구성을 도출하도록 돕는 기술을 개발했다.
KAIST(총장 이광형)는 전기및전자공학부 유민수 교수 연구팀은 삼성전자 삼성종합기술원과 공동연구를 통해, 대규모 분산 시스템에서 대형 언어 모델(LLM)의 학습 시간을 예측하고 최적화할 수 있는 시뮬레이션 프레임워크(이하 vTrain)를 개발했다고 13일 밝혔다.
대형 언어 모델 학습 효율을 높이려면 최적의 분산 학습 전략을 찾는 것이 필수적이다. 그러나 가능한 전략의 경우의 수가 방대할 뿐 아니라 실제 환경에서 각 전략의 성능을 테스트하는 데는 막대한 비용과 시간이 들어간다.
이에 따라 현재 대형 언어 모델을 학습하는 기업들은 일부 경험적으로 검증된 소수의 전략만을 사용하고 있다. 이는 GPU 활용의 비효율성과 불필요한 비용 증가를 초래하지만, 대규모 시스템을 위한 시뮬레이션 기술이 부족해 기업들이 문제를 효과적으로 해결하지 못하고 있는 상황이다.
이에 KAIST 연구팀은 vTrain을 개발해 대형 언어 모델의 학습 시간을 정확히 예측하고, 다양한 분산 병렬화 전략을 빠르게 탐색할 수 있도록 했다.
연구팀은 실제 다중 GPU 환경에서 다양한 대형 언어 모델 학습 시간 실측값과 vTrain의 예측값을 비교한 결과, 단일 노드에서 평균 절대 오차(MAPE) 8.37%, 다중 노드에서 14.73%의 정확도로 학습 시간을 예측할 수 있음을 검증했다.
연구팀은 삼성전자 삼성종합기술원와 공동연구를 진행하여 vTrain 프레임워크와 1,500개 이상의 실제 학습 시간 측정 데이터를 오픈소스로 공개(https://github.com/VIA-Research/vTrain)하여 AI 연구자와 기업이 이를 자유롭게 활용할 수 있도록 했다.
유민수 교수는 “vTrain은 프로파일링 기반 시뮬레이션 기법으로 기존 경험적 방식 대비 GPU 사용률을 높이고 학습 비용을 절감할 수 있는 학습 전략을 탐색하였으며 오픈소스를 공개하였다. 이를 통해 기업들은 초거대 인공지능 모델 학습 비용을 효율적으로 절감할 것이다”라고 말했다.
이 연구 결과는 방제현 박사과정이 제 1저자로 참여하였고 컴퓨터 아키텍처 분야의 최우수 학술대회 중 하나인 미국 전기전자공학회(IEEE)·전산공학회(ACM) 공동 마이크로아키텍처 국제 학술대회(MICRO)에서 지난 11월 발표됐다. (논문제목: vTrain: A Simulation Framework for Evaluating Cost-Effective and Compute-Optimal Large Language Model Training, https://doi.org/10.1109/MICRO61859.2024.00021)
이번 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단, 정보통신기획평가원, 그리고 삼성전자의 지원을 받아 수행되었으며, 과학기술정보통신부 및 정보통신기획평가원의 SW컴퓨팅산업원천기술개발(SW스타랩) 사업으로 연구개발한 결과물이다.
붙임 : 연구개요, 그림 설명,
□ 연구개요
배경
최근 ChatGPT, DeepSeek과 같은 초거대 언어 모델(LLM)이 다양한 산업 분야에서 활용되면서, 이를 학습하기 위한 대규모 GPU 클러스터의 운영과 최적화가 중요한 문제로 떠오르고 있다. 이러한 LLM은 수천에서 수만 개의 GPU를 활용하여 학습되며, 학습 과정을 어떻게 병렬화하고 분산시키느냐에 따라 학습 시간과 비용이 크게 달라진다.
하지만 가능한 분산 학습 전략의 경우의 수가 매우 많아, 기업들은 일부 검증된 소수 전략만을 써왔고 이로 인해 GPU 자원 활용이 비효율적이고 불필요한 비용이 증가하고 있다.
이러한 문제에도 불구하고, 최적의 학습 전략을 찾기 위한 정확하고 효율적인 시뮬레이션 기술이 부족한 실정이다. 대규모 시스템에서 직접 실험하려면 막대한 비용과 시간이 소요되므로, 다양한 학습 전략을 효과적으로 평가·최적화할 수 있는 시뮬레이션 기술이 필요하다. 이에 본 연구에서는 대규모 분산 학습에 걸리는 시간을 예측해 줄 수 있는 시뮬레이션 프레임워크인 vTrain을 개발했다.
2. 연구 내용

본 연구는 대규모 언어 모델 학습의 분산 병렬화 전략을 정밀하게 분석하고, 이를 바탕으로 학습 시간을 예측할 수 있는 시뮬레이션 프레임워크 vTrain을 개발하였다. vTrain은 실행 그래프를 기반으로 학습 과정을 연산 단위로 표현하고, 각 연산의 실행 시간을 프로파일링해 전체 학습 시간을 예측한다. 이를 위해 본 연구에서는 병렬화 기법에 따른 통신 패턴을 효과적으로 표현하는 실행 그래프 생성 방법과, 프로파일링 오버헤드를 최소화하는 연산 선별 기법을 제안하였다.

본 연구진은 vTrain의 예측 정확도를 검증하기 위해 실제 다중 GPU 시스템에서의 학습 시간을 측정하고 비교한 결과, 단일 노드(8개 A100 GPU) 환경에서는 평균 절대 오차(MAPE) 8.37%, 다중 노드(최대 512개 A100 GPU) 환경에서는 14.73%의 오차 범위를 나타냈다. 이를 통해 vTrain이 대규모 LLM 학습에서 신뢰할 수 있는 시뮬레이션 도구로 활용될 수 있음을 확인하였다.
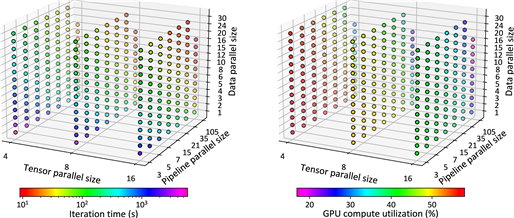
vTrain의 실제 활용 사례를 탐색하기 위해, 본 연구진은 특정 대형 언어 모델(예: MT-NLG)의 기존 학습 전략과 vTrain을 이용한 최적화 학습 전략을 비교하였다. 그 결과, 기존 경험적 방식 대비 GPU 사용률을 10% 이상 향상시키면서도 학습 비용을 5% 이상 절감할 수 있음을 확인하였다. 이외에도 클라우드 환경에서 다중 테넌트 GPU 클러스터 운영 최적화 및 주어진 컴퓨팅 자원 내에서 최적의 LLM 크기와 학습 토큰 수를 결정하는 문제와 같은 사례에서도 vTrain이 활용될 수 있음을 보였다.
3. 기대 효과
현재 대규모 언어 모델 학습에서 사용되는 병렬화 전략은 경험적 방식에 치중되어 있어, 최적 전략을 찾는 체계적인 분석이 필요한 상황이다. 본 연구에서 개발한 vTrain은 다양한 병렬화 기법을 정량적으로 평가하고 학습 시간을 예측할 수 있는 기능을 제공함으로써, 데이터센터 환경에서 최적의 분산 학습 전략을 수립하는 데 기여할 것으로 기대된다. 이를 통해 GPU 자원을 최대한 효율적으로 활용하고 학습 비용을 절감함과 동시에, 대규모 AI 시스템 운영의 효율성을 한층 높일 수 있을 것으로 전망된다.
□ 그림 설명
그림 1. vTrain 시뮬레이터 구조 모식도
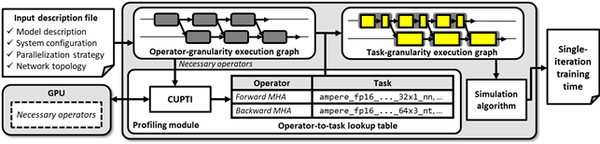
그림 2. 단일 노드 시스템(좌) 및 다중 노드 시스템(우)에 대한 학습 시간 측정값과 예측값의 비교

그림 3. 다양한 병렬화 기법에 따른 MT-NLG 학습 시간 및 GPU 사용률 변화

